Hazelcast MapReduce on GPU (APRIL'S FOOL!)
APRIL'S FOOL:
Sorry that I have to admit it was just an April's Fool. The interesting fact btw is that when I first came up with the idea it sounded like totally implausible but while writing I realized "hey that should actually be possible". Maybe not yet for a map-reduce framework but definitely to back up a distributed fractal calculation what is I will look into at the next time. If somebody want to team up on this I'm fully open for requests. Just don't hesitate to contact me.
While this was a prank at the current time, I'm really looking forward to eventually bring distributed environments like Hazelcast to the GPU - at least when Java 9 will feature OpenJDK Project Sumatra and a big thanks to the guys from AMD and Rootbeet that started all that movement!
Since the last decade RAM and CPU always got faster but still some calculations can be done faster in GPUs due to their nature of data. At Hazelcast we try to make distributed calculations easy and fast for everybody.
While having some spare time I came up with the idea of moving data calculations to the GPU to massively scale it out and since I created the map-reduce framework on the new Hazelcast 3.2 version it was just a matter of time to make it working with a GPU.
Disclaimer: Before you read on I want to make sure that you understand that this is neither an official Hazelcast project nor it is yet likely to be part of the core in the near future but as always you may expect the unexpected!
So as mentioned above I was playing around with Aparapi. Aparapi is a Java binding for transforming Javs bytecode into OpenCL code developed by AMD (Aparapi). There are similar projects going on so eventually we might see this working on all JVM by nature (OpenJDK Project Sumatra, Rootbeer) but currently Aparapi seems to be the only one that was working for me.
Before yoy can begin you have to make sure that your BIOS / mainboard support IOMMU which offers the possibility for CPU and GPU to access the same memory space. In addition to that you have to install multiple drivers and libraries. I just made some basic screenshots to step quickly through it.
The screenshots do not show the real process because I made them using a VirtualBox Mint VM. The original installation wasn't captured in screenshots :-(
For exact / updated installation steps please read the official setup manual: SettingUpLinuxHSAMachineForAparapi.
Another important thing is that this seems to work only on Ubuntu (and derivates) at the moment, especially because you need a custom kernel.
So lets quickly run through the installation steps to just make clear how it would work in general:
First step would be to setup your BIOS / UEFI to enable IOMMU on the operating system side. To see how this works please consult your mainboard manual (or Google that shit ;-)).
If this is fine you can go on installing the required drivers, kernels and libraries.
1. Install HSA enabled kernel + HSA driver:
$ cd ~ # I put all of this in my home dir
$ sudo apt-get install git
$ cd ~ # I put all of this in my home dir
$ git clone https://github.com/HSAFoundation/\
Linux-HSA-Drivers-And-Images-AMD.git

$ cd ~ # I put all of this in my home dir
$ curl -L https://github.com/HSAFoundation/\
Linux-HSA-Drivers-And-Images-AMD/archive/\
master.zip > drivers.zip
$ unzip drivers.zip
$ cd ~/Linux-HSA-Drivers-And-Images-AMD
$ echo "KERNEL==\"kfd\", MODE=\"0666\"" |\
sudo tee /etc/udev/rules.d/kfd.rules
$ sudo dpkg -i ubuntu13.10-based-alpha1/\
linux-image-3.13.0-kfd+_3.13.0-kfd+-2_amd64.deb
$ sudo cp ~/Linux-HSA-Drivers-And-Images-AMD/\
ubuntu13.10-based-alpha1/xorg.conf /etc/X11
$ sudo reboot

2. Install OKRA Runtime:
$ cd ~ # I put all of this in my home dir
$ git clone https://github.com/HSAFoundation/\
Okra-Interface-to-HSA-Device.git

$ cd ~ # I put all of this in my home dir
$ curl -L https://github.com/HSAFoundation/\
Okra-Interface-to-HSA-Device/archive/\
master.zip > okra.zip
$ unzip okra.zip
$ cd ~/Okra-Interface-to-HSA-Device/okra/samples/
$ sh runSquares.sh
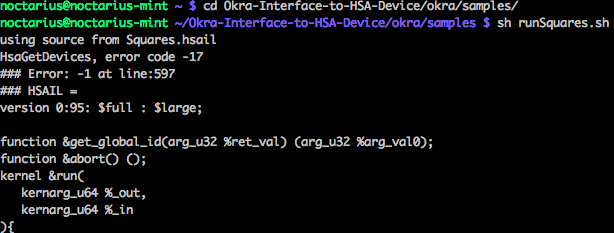
The last step should be successful on your machine if you want to try Aparapi on your own, essentially it failed on the VirtualBox VM :-)
3. Install OpenCL drivers:
Go to http://developer.amd.com/tools-and-sdks/heterogeneous-computing/amd-accelerated-parallel-processing-app-sdk/downloads and download the AMD-APP-SDK, I chose the same version as in the setup documentation 2.9.
$ cd ~
$ gunzip ~/Downloads/AMD-APP-SDK-v2.9-lnx64.tgz
$ tar xvf ~/Downloads/AMD-APP-SDK-v2.9-lnx64.tar
$ rm ~/default-install_lnx_64.pl ~/icd-registration.tgz\
~/Install-AMD-APP.sh ~/ReadMe.txt
$ gunzip ~/AMD-APP-SDK-v2.9-RC-lnx64.tgz
$ tar xvf ~/AMD-APP-SDK-v2.9-RC-lnx64.tar
$ rm ~/AMD-APP-SDK-v2.9-RC-lnx64.tar
$ rm -rf AMD-APP-SDK-v2.9-RC-lnx64/samples
4. Install Aparapi and build the JNI libs:
sudo apt-get install ant g++ subversion
svn checkout https://aparapi.googlecode.com/\
svn/branches/lambda aparapi-lambda
cd ~/aparapi-lambda
. env.sh
ant
And that should be it, now you should be able to run the examples.
After we installed Aparapi we now can have a look at Aparapi enabled map-reduce and what performance looks like.
Do to a limited set of datatypes the following example code looks kind of weird. Neither Strings nor char-array is supported at the moment so we do some hacks to map the String to a char-array first and then the char-array to and int-array and the other way back after calculation.
The example is using the well known word-count map-reduce "hello world" and is pretty much the same as in the Hazelcast map-reduce documentation, so I'll skip on how the Mapper, Combiner, Reducer will look like. I also guess most map-reduce users can guess the general part :-)
So let's have a look at the execution source:
public class HazelcastAparapi {
public static void main(String[] args) {
HazelcastInstance hz = newHazelcastInstance();
IMap<String, String> docs = hz.getMap("docs");
documents.addAll(readDocuments());
// Create a special JobTracker for use of Aparapi
JobTracker tracker = new AparapiJobTracker(hz);
// Special KeyValueSource to make access from GPU
// trough IOMMU possible.
// The int-array in reality is a char-array but
// char-arrays are not yet supported by Aparapi
KeyValueSource<int[], Long> source =
new AparapiKeyValueSource(docs);
// We have to work around the problem, that the
// GPU is only able to access similarly sized
// data value so we use a fixed sized int-array
Job<int[], Long> job = tracker.newJob(source);
// Now we define the map-reduce job as normally
// but we do not submit it since we have to pass
// it to the kernel
job.mapper(new WordCountMapper())
.combiner(new WordCountCombinerFactory())
.reducer(new WordCountReducerFactory());
// Initialize the Aparapi Kernel
Kernel kernel = new MapReduceAparapiKernel(job);
try {
// Fire up the execution
kernel.execute(HUGE);
// Retrieve the results
AparapiJob aj = (AparapiJob) job;
Map<int[], Long> result = aj.getResult();
// Remap the int-array (char-array) to strings
Map<String, Long> values = mapToStrings(result);
// Show the results
Set<...> entrySet = values.entrySet();
for (Map.Entry<String, Long> entry : entrySet) {
System.out.println(entry.getKey()
+ " was found " + entry.getValue()
+ " times.");
}
} finally {
// Shutdown the Aparapi kernel
kernel.dispose();
}
}
}
As mentioned before a int-array hack is necessary to make this code work. On the other hand we need to use a special JobTracker which is only slightly different from the original but returns a non distributed Job instance (sorry not yet working ;-)). In addition we have to instantiate a Aparapi kernel subclass which handles the offload to the GPU as well as transforming the Java bytecode into OpenCL for us.
public class MapReduceAparapiKernel
extends Kernel {
// ... left out code
public void run() {
// Test execution for GPU
EXECUTION_MODE em = kernel.getExecutionMode();
if (!em.equals(Kernel.EXECUTION_MODE.GPU)) {
throw new IllegalStateException(
"GPU execution not possible");
}
AparapiJob job = (AparapiJob) getJob();
job.execute(this);
}
}
The actual codebase is not very clean and looks more like a hack but I hope to opensource it anytime soon. Additionally this isn't yet very extended in it's use cases since there are many things that needs to be done and hacks are likely to be added a lot (char[] as int[]) but anyways I made a few quick performance tests with the original example from the documentation against the example above. Runtime only includes the runtime of the map-reduce operation itself and does not contain time to forward and backward map the strings to int[], so time measuring might be a little bit unfair :-)
In addition even the default Hazelcast example is only running on a single node at the moment since the Aparapi version isn't possible to be run in a distributed environment yet (sadly I don't have enough server machines at home to test that).
So what does the performance look like?
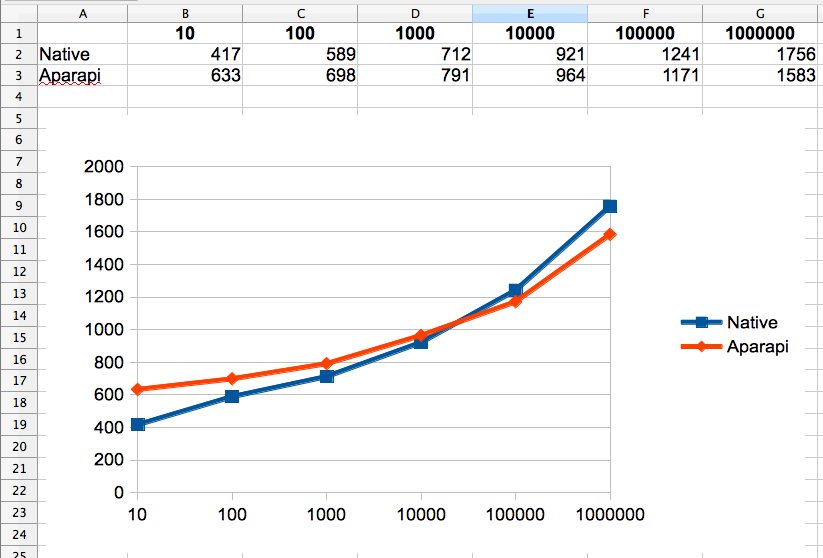
We see that the basic startup time for Aparapi seems a bit higher than on the default implementation of Hazelcast but it relativizes over the whole runtime. At the moment this is only a little bit faster but code is mostly hacked down and I'm not sure how much Aparapi is optimized or if Sumatra will bring better performance in the end.